
Dmitry Ulyanov an engineer at Samsung AI tweeted something remarkable two days ago. He was one of the contributors to the paper, so I assume that he was one of the inventors of this new form of digital manipulation. From his tweet,
“Another great paper from Samsung AI lab!
@egorzakharovdl et al. animate heads using only few shots of target person (or even 1 shot). Keypoints, adaptive instance norms and GANs, no 3D face modelling at all. “
First let me just acknowledge that I’m not sure if this could be considered art in the traditional sense, but probably in the near future movies, television, and video will all have to be second-guessed. You would have to wonder if the dignitary making a speech is really a person. Is he actually speaking, or is it an AI? It will be entirely possible that he had his face digitized and the subsequent speech could have been created for him. That’s possibly the best case scenario.

The relative ease that this can be done is what is so impressive. You don’t need a 3D model to create the talking head, you just need a photograph, I guess the more photos you use the better the result.

In the video on YouTube it shows six photos of an unnamed person that had been turned into a talking head. In some of the other examples they used selfies from Facebook to create a girl talking. The really interesting part, and is probably what excites me the most, is that they can do it with just one image. Think of it, take a photo and turn it into a talking head. Some of the examples that they used was Marilyn Monroe and the Mona Lisa.
Here is the paper written about it:
“Several recent works have shown how highly realistic human head images can be obtained by training convolutional neural networks to generate them. In order to create a personalized talking head model, these works require training on a large dataset of images of a single person. However, in many practical scenarios, such personalized talking head models need to be learned from a few image views of a person, potentially even a single image. Here, we present a system with such few-shot capability. It performs lengthy meta-learning on a large dataset of videos, and after that is able to frame few- and one-shot learning of neural talking head models of previously unseen people as adversarial training problems with high capacity generators and discriminators. Crucially, the system is able to initialize the parameters of both the generator and the discriminator in a person-specific way, so that training can be based on just a few images and done quickly, despite the need to tune tens of millions of parameters. We show that such an approach is able to learn highly realistic and personalized talking head models of new people and even portrait paintings.” –https://arxiv.org/abs/1905.08233v1
The one photograph statement isn’t exactly true, because it takes some comparing and integration of other images and video. If I understand the process completely. They take a photograph, or more than one, integrate into the AI of a person moving. In layman comparisons it could be considered mapping the face to the movements. The difference is that it appears to be all done by the computer.
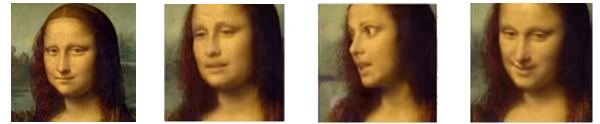
I’m still trying to digest the ramifications of this new technology. At the moment I read that they are not sharing it for obvious reasons. A person could easily be impersonated, although there are some limitations at the moment. The technology is rough. Right now the videos show distortion and could easily be detected as being computer generated. That’s right now though. I could have said the exact same thing about cgi in movies no more than ten years ago. How long will this technology be rough and unrefined? Will we even know if they’ve worked out the bugs? These questions will only be answered in time, and probably less time than we expect.